SLURM
Slurm (Simple Linux Usage Resource Manager) is used to configure, run and otherwise manage jobs on the HPC. From the Slurm quick start guide:
“Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. …
As a cluster workload manager, Slurm has three key functions. First, it allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work. Second, it provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes. Finally, it arbitrates contention for resources by managing a queue of pending work.”
System Specifications
If you want to know the system specifications for DeepThought, head on over to here
SLURM on DeepThought
SLURM on DeepThought uses the ‘Fairshare’ work allocation algorithm. This works by tracking how many resource your job takes and adjusting your position in queue depending upon your usage. The following sections will break down a quick overview of how we calculate things, what some of the cool-off periods are and how it all slots together.
In a sentence, what does this mean for you?
Greedy users have to wait to run jobs - but only if there are people ahead of them!
What will it mean in the future?
Greedy users will have to wait to start jobs and if they are running a job with a ‘non-greedy’ person waiting, their job will be forcibly paused to let the other person run their job.
SLURM Priority
The ‘Priority of a job is a number you get at the end of the Fairshare calculation. This is attached to your user and is inherited by accounts(colleges). For example, a system might have 1000 ‘Shares’ - think of them as a arbitrary concept of ‘some form of computation’. Then the individual ‘College’ Accounts would be divvied up as needed for all the users that are within that college.
At any point, you can check the ‘live’ priority scores of user accounts via the command:
sprio
Which will print something resembling this table:

If you want to interrogate even more data, you can explore the command:
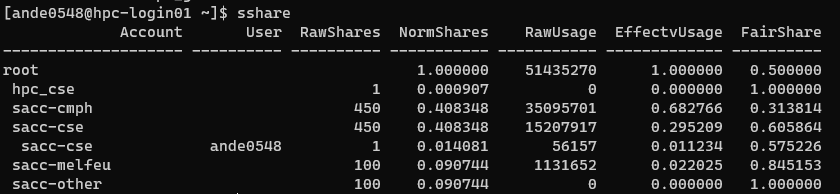
sshare
Which will allow for greater details of how your score was calculated.
Calculating Priority
SLURM tracks ‘Resources’. This can be nearly anything on the HPC - CPU’s, Power, GPU’s, Memory, Storage, Licenses, anything that the HPC needs to track usage and allocation.
The basic premise is - you have:
Weight
Factor
Unit(s)
Then you multiple all three together to get your end priority. So, lets say you ask for 2 GPU’s (The current max you can ask for)
A GPU on DeepThought (when this was written) is set to have these parameters:
Weight: 5
Factor: 1000
So your final equation is basically:
2 x (5 x 1000) = 10,000
There is a then a lot of math to normalize your score against capacity, current cluster utilization, other users comparative usage, how big you job is, favor status, shares available, account shares percentages and a lot more. There are a lot of moving parts and its quite complicated! But why are the number so big? So that we have finer-grained priority and we can avoid ‘collisions’ where two individual users have the same priority number.
Requested Vs. Utilized
This ‘Fairshare’ score is part of the reason why you must tailor your SLURM scripts or risk your priority hitting rock bottom. If you ask for and entire standard node (64 CPU’s + 256GB RAM) you will be ‘charged’ for that amount - even if you are only using a tiny percentage of those actual resources. This is a huge amount of resources, and will very quickly drop your priority!
To give you an idea of the initial score you would get for consuming an entire node, which is then influences by other factors:
CPU: 64 * 1 * 1000 = 64,000 (Measure Per CPU Core)
RAM: 256 * 0.25 * 1000 = 64,000 (Measured Per GB)
Total: 128,000
So, its stacks up very quickly, and you really want to write your job to ask for what it needs, and not much more! This is not the number you see and should only be taken as an example. If you want to read up on exactly how Fairshare works, then head on over to here.
SLURM: The Basics
These are some of the basic commands. The Slurm Quick-Start guide is also very helpful to acquaint yourself with the most used commands.
Slurm has also produced the Rosetta Stone - a document that shows equivalents between several workload managers.
Job submission
Once the Slurm script is modified and ready to run, go to the location you have saved it and run the command:
sbatch <name of script>.sh
To test your job use:
sbatch --test-only <name of script>.sh
This does not actually submit anything. Useful for testing new scripts for errors.
Job information
List all current jobs for a user:
squeue -u <username>
List all running jobs for a user:
squeue -u <username> -t RUNNING
List all pending jobs for a user:
squeue -u <username> -t PENDING
List all current jobs in the shared partition for a user:
squeue -u <username> -p shared
List detailed information for a job (useful for troubleshooting):
scontrol show jobid -dd <jobid>
Cancelling a job
To cancel a job based on the jobid, run the command:
scancel <jobid of the job to cancel>
To cancel a job based on the user, run the command:
scancel -u <username of job to cancel>
To cancel all the pending jobs for a user:
scancel -t PENDING -u <username>
To cancel one or more jobs by name:
scancel --name myJobName
To hold a particular job from being scheduled:
scontrol hold <jobid>
To release a particular job to be scheduled:
scontrol release <jobid>
To requeue (cancel and rerun) a particular job:
scontrol requeue <jobid>
SLURM: Advanced
Job Arrays
Job arrays is a popular strategy to process large numbers of the same workflow repetitively in one go, often reducing analytical time significantly. Job arrays are also often refereed as embarrassingly/pleasingly parallel processes. For more information, see SLURM Job Arrays.
To cancel an indexed job in a job array:
scancel <jobid>_<index>
To find the original submit time for your job array:
sacct -j 32532756 -o submit -X --noheader | uniq
The following are good for both jobs and job arrays. Commands can be combined to allow efficiency and flexibility.
Suspend all running jobs for a user (takes into account job arrays):
squeue -ho %A -t R | xargs -n 1 scontrol suspend
Resume all suspended jobs for a user:
squeue -o "%.18A %.18t" -u <username> | awk '{if ($2 =="S"){print $1}}' | xargs -n 1 scontrol resume
After resuming, check if any are still suspended:
squeue -ho %A -u $USER -t S | wc -l
The following is useful if your group has its own queue and you want to quickly see usage:
lsload |grep 'Hostname \|<partition>'
Environmental Variables
There are environment variables set by both SLURM and the HPC to manipulate jobs and their execution.
SLURM Specific Environment Variables
The following variables are set per job, and can be access from your SLURM Scripts if needed.
| Variable Name | Description |
|---|---|
| $SLURM_JOBID | Job ID. |
| $SLURM_JOB_NODELIST | Nodes allocated to the job i.e. with at least once task on. |
| $SLURM_ARRAY_TASK_ID | If an array job, then the task index. |
| $SLURM_JOB_NAME | Job name. |
| $SLURM_JOB_PARTITION | Partition that the job was submitted to. |
| $SLURM_JOB_NUM_NODES | Number of nodes allocated to this job. |
| $SLURM_NTASKS | Number of tasks (processes) allocated to this job. |
| $SLURM_NTASKS_PER_NODE | (Only set if the --ntasks-per-node option is specified) Number of tasks (processes) per node. |
| $SLURM_SUBMIT_DIR | Directory in which job was submitted. |
| $SLURM_SUBMIT_HOST | Host on which job was submitted. |
| $SLURM_PROC_ID | The process (task) ID within the job. This will start from zero and go up to $SLURM_NTASKS-1. |
DeepThought Set Environment Variables
The DeepThought HPC will set some additional environment variables to manipulate some of the Operating system functions. These directories are set at job creation time and then are removed when a job completes, crashes or otherwise exists.
This means that if you leave anything in $TMP, $BGFS or $SHM directories it will be removed when your job finishes.
To make that abundantly clear. If the Job creates /cluster/jobs/$SLURM_JOB_USER/$SLURM_JOB_ID (the $BGFS location) it will also delete that entire directory when the job completes. Ensure that your last step in any job creation is to move any data you want to keep to /scratch or /home.
| Variable Name | Description | Value |
|---|---|---|
| $TMP | The Linux default 'Temp' file path. | /local/$SLURM_USER/$SLURM_JOB_ID |
| $TMPDIR | An alias for $TMP | /local/$SLURM_USER/$SLURM_JOB_ID/ |
| $TMP_DIR | An alias for $TMP | /local/$SLURM_USER/$SLURM_JOB_ID/ |
| $TEMP | An alias for $TMP | /local/$SLURM_USER/$SLURM_JOB_ID/ |
| $TEMPDIR | An alias for $TMP | /local/$SLURM_USER/$SLURM_JOB_ID/ |
| $TEMP_DIR | An alias for $TMP | /local/$SLURM_USER/$SLURM_JOB_ID/ |
| $BGFS | The writable folder in /cluster for you job | /cluster/jobs/$SLURM_JOB_USER/$SLURM_JOB_ID |
| $BGFS_DIR | An alias for $BGFS | /cluster/jobs/$SLURM_JOB_USER/$SLURM_JOB_ID |
| $BGFSDIR | An alias for $BGFS | /cluster/jobs/$SLURM_JOB_USER/$SLURM_JOB_ID |
| $SHM_DIR | A Per-Job Folder on the Compute Node Shared-Memory / Tempfs Mount | /dev/shm/jobs/$USER/ |
| $OMP_NUM_THREADS | The OpenMP CPU Count Environment Variable | $SLURM_CPUS_PER_TASK |
$TMPDIR and SLURM Job-Arrays
[ande0548@hpcdev-head01 slurm]$ sbatch --array=0-5 tmpdir_increment.sh
Submitted batch job 502
[ande0548@hpcdev-head01 slurm]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
502_0 general tmpdir_.s ande0548 R 0:00 1 hpcdev-node001
502_1 general tmpdir_.s ande0548 R 0:00 1 hpcdev-node001
502_2 general tmpdir_.s ande0548 R 0:00 1 hpcdev-node001
502_3 general tmpdir_.s ande0548 R 0:00 1 hpcdev-node001
502_4 general tmpdir_.s ande0548 R 0:00 1 hpcdev-node002
502_5 general tmpdir_.s ande0548 R 0:00 1 hpcdev-node002
[ande0548@hpcdev-head01 slurm]$ ls
slurm-502_0.out slurm-502_1.out slurm-502_2.out slurm-502_3.out slurm-502_4.out slurm-502_5.out tmpdir_increment.sh
[ande0548@hpcdev-head01 slurm]$ cat slurm-502_0.out
TMP: /local/jobs/ande0548/503
TMPDIR: /local/jobs/ande0548/503
JOB ID: 503
TASK ID: 0
[ande0548@hpcdev-head01 slurm]$ cat slurm-502_1.out
TMP: /local/jobs/ande0548/504
TMPDIR: /local/jobs/ande0548/504
JOB ID: 504
TASK ID: 1
Notice that the $TMP directories are different for every step in the array? This ensures that each job will never collide with another jobs $TMP, even if they are running on the same node.
To reiterate the warning above - if you leave anything in the $TMP or $SHM Directories, SLURM will delete it at the end of the job, so make sure you move any results out to /scratch or /home.
Filename Patterns
Some commands will take a filename. The following modifiers will allow you to generate files that are substituted with different variables controlled by SLURM.
| Symbol | Substitution |
|---|---|
| \\ | Do not process any of the replacement symbols. |
| %% | The character "%". |
| %A | Job array's master job allocation number. |
| %a | Job array ID (index) number. |
| %J | Jobid.stepid of the running job. (e.g. "128.0") |
| %j | Jobid of the running job. |
| %N | Short hostname. This will create a separate IO file per node. |
| %n | Node identifier relative to current job (e.g. "0" is the first node of the running job) This will create a separate output file per node. |
| %s | Stepid of the running job. |
| %t | Task identifier (rank) relative to current job. This will create a separate output file per task. |
| %u | User name. |
| %x | Job name. |
SLURM: Extras
Here is an assortment of resources that have been passed on to the Support Team as ‘Useful to me’. Your mileage may vary on how useful you find them.
Tasks, jobs & parallel scripting
Besides useful commands and ideas, this FAQ has been the best explanation of ‘going parallel’ and the different types of parallel jobs, as well as a clear definition for what is considered a task.
An excellent guide to submitting jobs.
SLURM: Script Template
#!/bin/bash
# Please note that you need to adapt this script to your job
# Submitting as is will fail cause the job to fail
# The keyword command for SLURM is #SBATCH --option
# Anything starting with a # is a comment and will be ignored
# ##SBATCH is a commented-out #SBATCH command
# SBATCH and sbatch are identical, SLURM is not case-sensitive
##################################################################
# Change FAN to your fan account name
# Change JOBNAME to what you want to call the job
# This is what is shows when attempting to Monitor / interrogate the job,
# So make sure it is something pertinent!
#
#SBATCH --job-name=FAN_JOBNAME
#
##################################################################
# If you want email updates form SLURM for your job.
# Change MYEMAIL to your email address
#SBATCH --mail-user=MYEMAIL@flinders.edu.au
#SBATCH --mail-type=ALL
#
# Valid 'points of notification are':
# BEGIN, END, FAIL, REQUEUE.
# ALL means all of these
##################################################################
# Tell SLURM where to put the Job 'Output Log' text file.
# This will aid you in debugging crashed or stalled jobs.
# You can capture both Standard Error and Standard Out
# %j will append the 'Job ID' from SLURM.
# %x will append the 'Job Name' from SLURM
# %
#SBATCH --output=/home/$FAN/%x-%j.out.txt
#SBATCH --error=/home/$FAN/%x-%j.err.txt
##################################################################
# The default partition is 'general'.
# Valid partitions are general, gpu and melfu
##SBATCH --partition=PARTITIONNAME
#
##################################################################
# Tell SLURM how long your job should run for as a hard limit.
# My setting a shorter time limit, it is more likely that your
# job will be scheduled when attempting to backfill jobs.
#
# The current cluster-wide limit is 14 Days from Start of Execution.
# The timer is only active while your job runs, so if you suspend
# or pause the job, it will stop the timer.
#
# The command format is as follows: #SBATCH --time=DAYS-HOURS
# There are many ways to specify time, see the SchedMD Slurm
# manual pages for more.
#SBATCH --time=14-0
#
##################################################################
# How many tasks is your job going to run?
# Unless you are running something that is Parallel / Modular or
# pipelined, leave this as 1. Think of each task as a 'bucket of
# resources' that stand alone. Without MPI / IPC you can't talk to
# another bucket!
#
#SBATCH --ntasks=1
#
# If each task will need more that a single CPU, then alter this
# value. Remember, this is multiplicative, so if you ask for
# 4 Tasks and 4 CPU's per Task, you will be allocated 16 CPU's
#SBATCH --cpus-per-task=1
##################################################################
# Set the memory requirements for the job in MB. Your job will be
# allocated exclusive access to that amount of RAM. In the case it
# overuses that amount, Slurm will kill the job. The default value is
# around 2GB per CPU you ask for.
#
# Note that the lower the requested memory, the higher the
# chances to get scheduled to 'fill in the gaps' between other
# jobs. Pick ONE of the below options. They are Mutually Exclusive.
# You can ask for X Amount of RAM per CPU (MB by default).
# Slurm understands K/M/G/T For Kilo/Mega/Giga/Tera Bytes.
#
#SBATCH --mem-per-cpu=4000
# Or, you can ask for a 'total amount of RAM'. If you have multiple
# tasks and ask for a 'total amount' like below, then SLURM will
# split the total amount to each task evenly for you.
##SBATCH --mem=12G
##################################################################
# Change the number of GPU's required for you job. The most GPU's that can be
# requested is 2 per node. As there are limited GPU slots, they are heavily
# weighted against for Fairshare Score calculations.
# You can request either a 'gpu:telsa_v100:X' or a 'gpu:x'
#
# You can either request 0, or omit this line entirely if you
# a GPU is not needed.
#
#SBATCH --gres="gpu:0"
##################################################################
# Load any modules that are required. This is exactly the same as
# loading them manually, with a space-separated list, or you can
# write multiple lines.
# You will need to uncomment these.
#module load miniconda/3.0 cuda10.0/toolkit/10.0.130
#module load miniconda/3.0
#module load cuda10.0/toolkit/10.0.130
##################################################################
# This example script assumes that you have already moved your
# dataset to /scratch as part of your HPC Pre-Job preparations.
# Its best to use the $TMP/$TMPDIR setup for you here
# to allow for the HPC to auto-clean anything you
# leave behind by accident.
# If you have a job-array and need a shared directory for
# data on /local, you will need to manually cleanup that
# directory as a part of your job script.
# Example using the SLURM $BGFS Variable (the Parallel Filesystem)
cd $BGFS
cp /scratch/user/<FAN>/dataset ./
##################################################################
# Enter the command-line arguments that you job needs to run.
##################################################################
# Once you job has finished its processing, copy back your results
# and ONLY the results to /scratch, then clean-up the temporary
# working directory
# This command assumes that the destination exists
cp -r /$BGFS/<OUTPUT_FOLDER> /scratch/user/<FAN>/<JOB_RESULT_FOLDER>
# No need to cleanup $BGFS, SLURM handles the cleanup for you.
# Just dont forget to copy out your results, or you will lose them!
##################################################################